머신러닝 알고리즘
지도학습 : 훈련하기 위한 데이터와 정답이 필요하다.
비지도학습 : 사람의 감독 없이 하기에 라벨이 지정되어 있지 않은 데이터를 이용한다.
지도학습
입력(input) : 데이터
타겟(target) : 정답
훈련 데이터 = 입력 + 타겟
특성 : 길이와 무게 처럼 데이터를 이루는 특징
데이터
훈련 세트 : 머신러닝을 훈련할 때 사용하는 데이터
데이터 세트 : 평가에 사용하는 데이터
샘플 : 하나의 데이터 세트 (ex, 도미의 길이+무게)


샘플링 편향
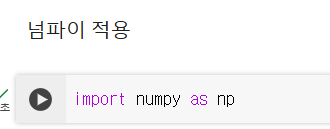
훈련과 데이터 세트를 나눴을 때 앞쪽은 도미, 뒷쪽은 빙어가 있게 된다.
이런 상태에서 뒤를 타겟 데이터로 지정하면 충분한 빙어 데이터가 들어가지 않기에 정답을 맞출 수가 없다.
-> 그러므로 골고루 섞는 과정이 필요하다.
넘파이
파이썬의 대표적인 배열 라이브러리
고차원 배열을 손쉽게 만들 수 있다.


무작위로 섞으면 입력과 타겟이 같은 인덱스를 가지고 갈 수 없기 때문에
넘파이의 랜덤 시드를 지정하여 사용했다.
arrange() 함수를 이용하여 0부터 48까지 증가하는 인덱스를 만들었다.
그리고 두개를 이용하여 shuffle() 함수로 섞었다.



머신러닝 프로그램 테스트
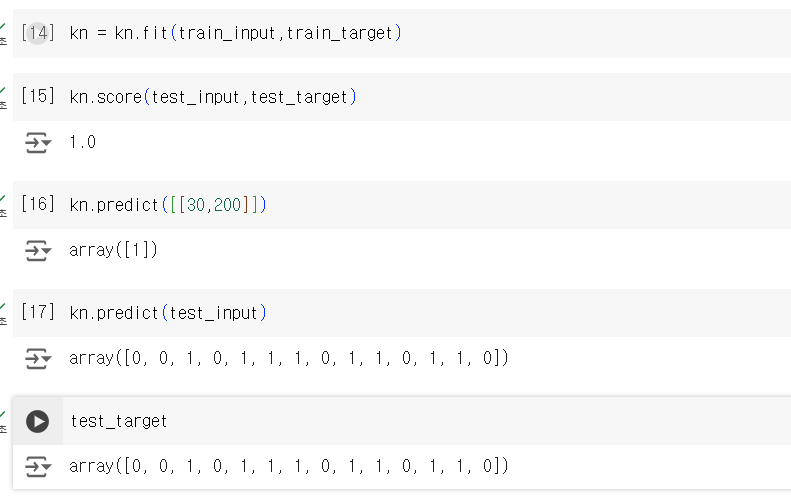
전과 같이 k-최근접 이웃 모델을 훈련시켜 사용해보니
데이터를 넣을때 옳은 답을 주었고
예측치와 정답지가 같게 나왔다.
과제
확인문제
Q1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용 할 수 있는 학습방법
A1. 지도 학습
지도학습은 데이터와 정답이 있을 때 사용하는 학습 방법이다.
Q2. 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상
A2. 샘플링 편향
이런 상태에서 뒤를 타겟 데이터로 지정하면 충분한 빙어 데이터가 들어가지 않기에 정답을 맞출 수가 없다.
-> 그러므로 골고루 섞는 과정이 필요하다.
Q3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
A3. 행 : 샘플, 열 : 특성
좌측을 행, 윗쪽이 열을 의미하기에
행은 각각의 데이터 샘플을 의미하고(생선)
열은 각각 길이와 무게가 들어갔었다.

'프로그래밍 > 인공지능' 카테고리의 다른 글
| [혼공머신] Chapter3-1 k-최근접 이웃 회귀 (2) | 2025.01.17 |
|---|---|
| [혼공머신]Chapter 2-2 데이터 전처리 (1) | 2025.01.12 |
| [혼공머신] Chapter 1-3. 생선 분류 문제 (1) | 2025.01.08 |
| [혼공머신] Chapter 1-1, 1-2 : 인공지능 및 코랩 (0) | 2025.01.07 |